Career Guide
5/7/2026•Avneesh Panwar
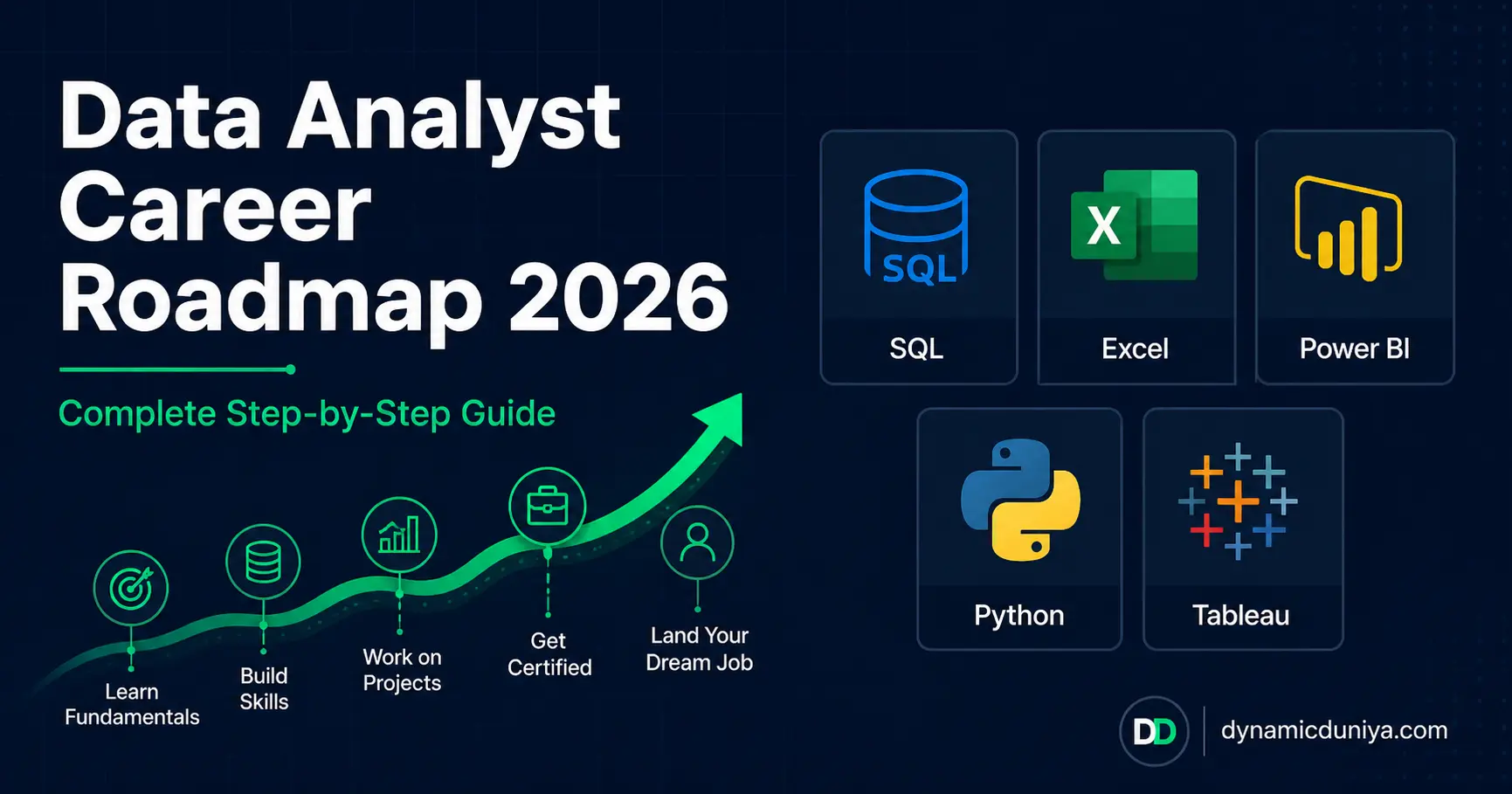
Data Analyst Career Roadmap 2026 — Complete Step-by-Step Guide
A complete data analyst career roadmap for 2026 — covering skills, tools, salary in India, portfolio projects, and a step-by-step learning path from absolute beginner to job-ready. Whether you are a fresher, a career switcher, or someone planning to enter data analytics, this guide tells you exactly what to learn, in what order, and how to get hired.
Read Article